On Screen Display (OSD) Alphabet
Strings can often provide solid clues or anchors when reversing code, as the strings referenced often give away the purpose of a piece of code in human-readable terms. The problem with the 2465 readout system, in this respect, is that the strings are all written in the readout system’s alphabet.
Locating the OSD strings and converting them to ASCII would greatly help the reversing effort, so that’s what I did.
Deciphering
In order to decipher the OSD alphabet it’s necessary to understand how the readout system works. Thankfully, the “Theory of Operation” (ToO) section in the service manuals has a solid explanation of how the readout system renders the contents of character RAM to the CRT, through the contents of the character ROM.
The ToO describes how the circuitry works in excruciating detail, but the gist of it is this:
-
A byte in the readout RAM selects a character to display.
The start address of the character in character ROM is simply the readout RAM byte value * 16.
-
Readout characters comprise a series of dots.
Each dot is encoded into a byte, where the X, Y coordinates of each dot are respectively encoded in 3 and 4 bits of the byte. This means each character can be as wide as 8 dots, but as tall as 16.
-
A dot with the MSB clear ends the character.
The way this is laid out is that some characters are designed to be used in pairs to make a single large character. As the end goal is to be able to convert a series of OSD bytes into a human-readable string, these pairwise characters are considered a single character for our purposes.
After some experimentation, I wrote a relatively simple python script to convert the character ROM to a bunch of PNG files.
Initially I assumed that “small” characters would be 8x8 while the dual “large” characters would be 16x16. This is however not true. There are several “small” characters that extend below the 8 row boundary. All the small characters below are rendered to 16 rows, though few use the space.
The Alphabet
I wager that the organization of this alphabet is largely determined by the glyphs Tektronix wanted to display. Note that any glyph that needs more than 16 dots will consume the subsequent character position, so there are several gaps in the character codes. The first subsumed code is 0x03, followed by 0x07 and 0x0B.
It’s also interesting to note that all the digits occur 4 times in this alphabet, as they appear both large and small, as well as with and without a decimal point.
| Code | Character |
|---|---|
| 0x00 | 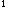 |
| 0x0201 | 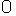 |
| 0x04 | 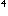 |
| 0x0605 | 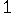 |
| 0x08 | 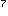 |
| 0x0A09 | 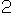 |
| 0x0C | 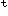 |
| 0x0E0D | 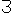 |
| 0x0F | 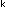 |
| 0x10 | 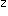 |
| 0x1211 | 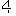 |
| 0x13 |  |
| 0x14 | 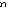 |
| 0x1615 | 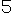 |
| 0x18 | 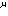 |
| 0x1A19 | 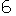 |
| 0x1C | 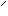 |
| 0x1E1D | 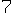 |
| 0x1F | 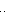 |
| 0x20 | 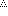 |
| 0x2221 | 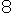 |
| 0x24 | 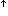 |
| 0x2625 | 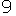 |
| 0x28 | 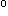 |
| 0x2A | 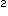 |
| 0x2B | 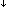 |
| 0x2C | 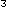 |
| 0x2D | 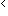 |
| 0x2E | 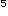 |
| 0x30 | 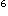 |
| 0x31 | 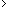 |
| 0x32 | 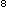 |
| 0x34 | 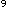 |
| 0x35 | 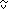 |
| 0x36 | 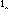 |
| 0x3837 | 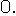 |
| 0x3A | 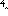 |
| 0x3C3B | 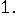 |
| 0x3E | 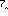 |
| 0x403F | 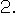 |
| 0x42 | 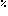 |
| 0x4443 | 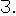 |
| 0x46 | 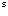 |
| 0x4847 | 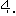 |
| 0x4A | 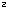 |
| 0x4C4B | 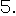 |
| 0x4E | 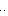 |
| 0x504F | 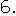 |
| 0x52 |  |
| 0x5453 | 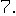 |
| 0x56 |  |
| 0x5857 | 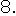 |
| 0x5A | 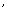 |
| 0x5C5B | 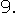 |
| 0x5E | 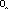 |
| 0x60 | 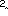 |
| 0x62 | 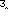 |
| 0x64 | 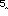 |
| 0x66 | 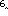 |
| 0x68 | 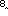 |
| 0x6A | 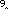 |
| 0x6C | 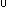 |
| 0x6E6D | 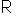 |
| 0x70 | 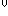 |
| 0x7271 | 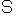 |
| 0x74 | 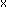 |
| 0x7675 | 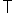 |
| 0x78 | 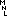 |
| 0x7B7A | 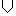 |
| 0x7C | 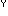 |
| 0x7D |  |
| 0x7E | 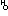 |
| 0x8180 | 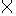 |
| 0x82 | 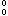 |
| 0x84 | 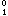 |
| 0x86 | 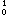 |
| 0x88 | 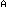 |
| 0x8A | 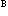 |
| 0x8C | 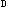 |
| 0x8E | 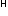 |
| 0x90 | 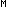 |
| 0x92 | 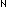 |
| 0x94 | 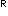 |
| 0x96 | 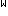 |
| 0x98 | 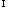 |
| 0x9A99 | 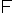 |
| 0x9C | 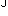 |
| 0x9E9D | 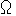 |
| 0xA0 | 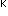 |
| 0xA2A1 | 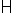 |
| 0xA5A4 | 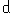 |
| 0xA6 |  |
| 0xA7 | 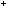 |
| 0xA8 | 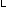 |
| 0xA9 | 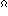 |
| 0xAA | 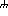 |
| 0xAC | 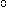 |
| 0xAEAD | 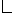 |
| 0xB0 | 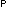 |
| 0xB1 |  |
| 0xB2 | 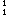 |
| 0xB4 | 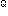 |
| 0xB5 | 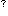 |
| 0xB6 | 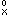 |
| 0xB8 | 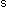 |
| 0xBAB9 | 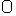 |
| 0xBC | 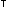 |
| 0xBD | 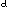 |
| 0xBE | 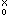 |
| 0xC0 | 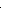 |
| 0xC2C1 |  |
| 0xC4 | 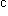 |
| 0xC6C5 | 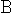 |
| 0xC8 | 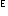 |
| 0xCAC9 | 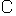 |
| 0xCC | 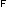 |
| 0xCECD | 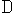 |
| 0xD0 | 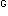 |
| 0xD2D1 | 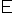 |
| 0xD4 |  |
| 0xD6D5 | 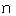 |
| 0xD8D7 | 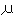 |
| 0xDAD9 | 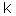 |
| 0xDCDB | 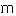 |
| 0xDFDE | 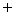 |
| 0xE0 |  |
| 0xE2E1 | 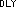 |
| 0xE4 | 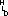 |
| 0xE6 | 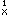 |
| 0xE8 | 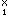 |
| 0xEA | 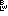 |
| 0xEC | 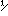 |
| 0xED |  |
| 0xEE | 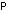 |
| 0xF0 |  |
| 0xF1 |  |
| 0xF3F2 | 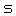 |
| 0xF5F4 | 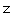 |
| 0xF6 |  |
| 0xF7 |  |
| 0xF8 | 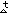 |
| 0xFA |  |
| 0xFB | 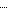 |
| 0xFC | 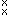 |
| 0xFE | 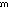 |